The internet, and the World Wide Web are based on plain text.
Everything on the web is plain text: .html, .css and .js files. (Pictures, audio and video aren’t in plain text of course – but they were added on the web much later.) To be a productive web designer, you need to be able to efficiently edit text files – and even several ones at once.
In 1989, when Tim Berners-Lee and Robert Cailliau invented HTTP and HTML, there was no “visual” world wide web. The world would have to wait until the launch of Mosaic to have a “graphical browser”.
For years, and even decades, computer networks were criss-crossed by typing commands in Terminals and using text-only tools like FTP for transferring files or various text editors (from nano to Vim and Emacs) to create and edit them.
A problem of scale
Because the World Wide Web was given to the world – and not sold or licensed – the popularity of HTTP/HTML caught on like wild fire.
Soon hundreds, then thousands then millions of servers went online. Web pages became web sites, the number of pages on sites skyrocketed and soon the number of web pages became unmanageable for human beings.
The solution was simple. The text in the HTML pages – in so-called “static web sites” – would have to be stored in a machine readable format and the web pages themselves would become templates that automatically pulled the information from database servers.
This is what was first called “dynamic web design“.
From “free-form” text to properly “structured” text
For Web Designers, the main issue was how to format the information previously contained inside the web pages. Human beings and computers do not read text the same way at all.
Also, the need to be able to search for specific information meant that the data had to be organized in logical way so that the computers could perform fast searches.
In other words, the text had to be organized into neat columns and rows such as in a spreadsheet. In a database, each table looks very much like a worksheet in Microsoft Excel (or any other spreadsheet application actually).
Examples
Free-form text (.txt)
Let’s say you want to build a collection of photographs you want to put online in a dynamic web site.
Your first photograph might have information like this:
Title: Photograph of a sunset
Author: John Smith
Location: Tunisia
Orientation: landscape
Keywords: sunset, landscape, Africa, Tunisia, horizontal
However organized this piece of information is to the human eye, it doesn’t work well in a spreadsheet. Notice how all the text is in one column. Specifically, the paragraph returns in the text became rows, but there is nothing marking the end of one column and the beginning of the other.
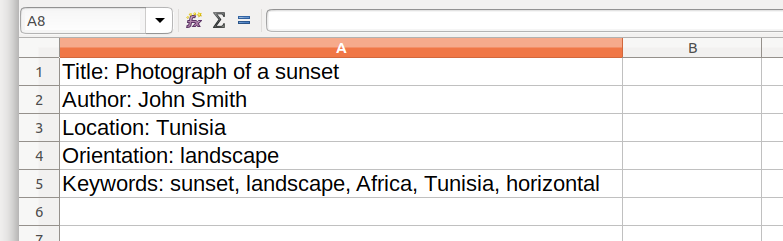
The above illustration would force the computer to search through all the text to find a specific piece of information. If there was many photos in the database, this would be very inefficient – ie slow.
The solution is to break down the text into specific columns and rows.
Comma separated values (.csv)
Using commas, the designers can mark the limit of one column and the beginning of the next. Notice how the commas do not show up in the spreadsheet.
Please note that words (plural) that belong in one field (such as firstname + lastname in the “name” field) should be placed in between quotation marks.
Title:, "Photograph of a sunset"
Author:, "John Smith"
Location:, Tunisia
Orientation:, landscape
Keywords:, sunset, landscape, Africa, Tunisia, horizontal
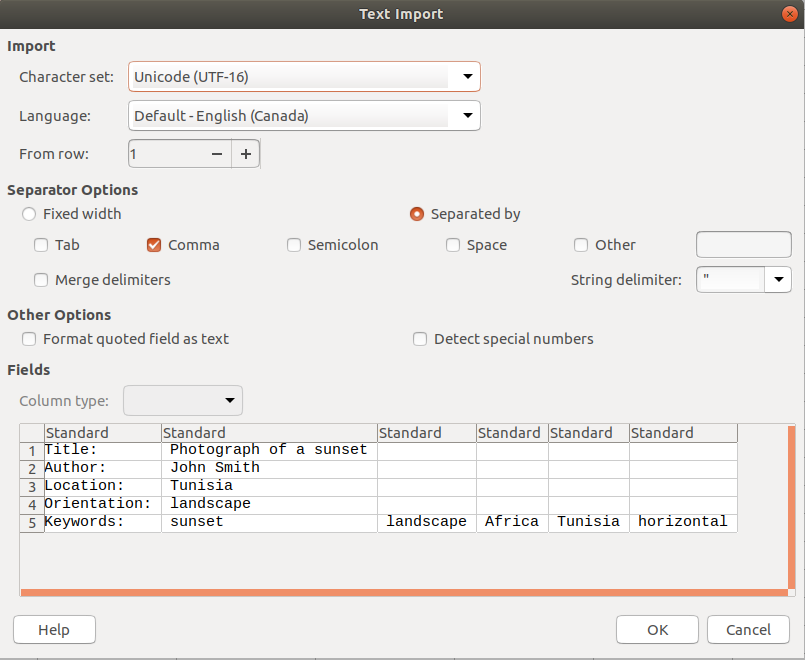
Importing the text into a spreadsheet application.
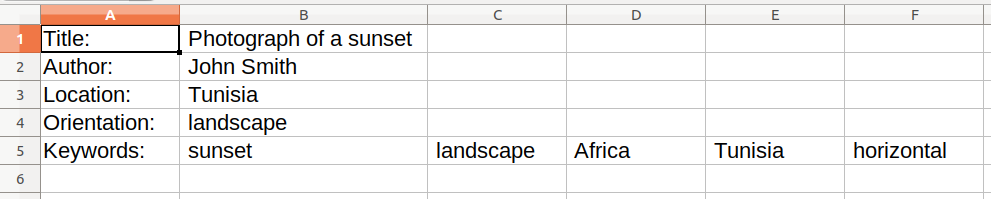
View of the data inside the spreadsheet.
Dirty data: GIGO (Garbage In / Garbage Out)
As a designer, or anyone with a flair for typography, you can see that this data has a problem. The words in the first column all have a colon added (“:”). To make things worse, the data in the first column is OK, but all the text in the second column starts with a space.
This is really bad because the space character is an actual character for the computer. If someone tries to search for an author with their first name starting with the letter J (as in “John”) the search will not work because the field contains “space-J”, in other words ” John”.
This is what we call “dirty” data. Designers and developers often get get dirty data from their customers. It is often referred to as “Garbage In Garbage Out“, meaning that if the data coming in is bad, the web site search system will be proportionately just as bad.
The solution therefore is to clean up the extra characters (colons and spaces).
Title,"Photograph of a sunset"
Author,"John Smith"
Location,Tunisia
Orientation,landscape
Keywords,sunset,landscape,Africa,Tunisia,horizontal

Importing the text into a spreadsheet application.

View of the data inside the spreadsheet.
The data is now much cleaner and better organized. However, it still isn’t perfect. How would you use this spreadsheet to serve more than one image? Where does the second picture go?
The answer is to move the labels (such as “title” or “author”) to the row at the top of the cells. The rows below would become each page.
Columns and Rows, please
The last step is to format the data into two lines: one for the type of information that will go in the columns (title, author, etc) and then the actual information that goes into those fields.
We remove the commas in between the keywords because we want all the keywords to be in single field together. (Or we could always make multiple keyword fields such as keyword1, keyword2, etc).
Title,Author,Location,Orientation,Keywords
"Photograph of a sunset","John Smith",Tunisia,landscape,sunset landscape Africa Tunisia horizontal,
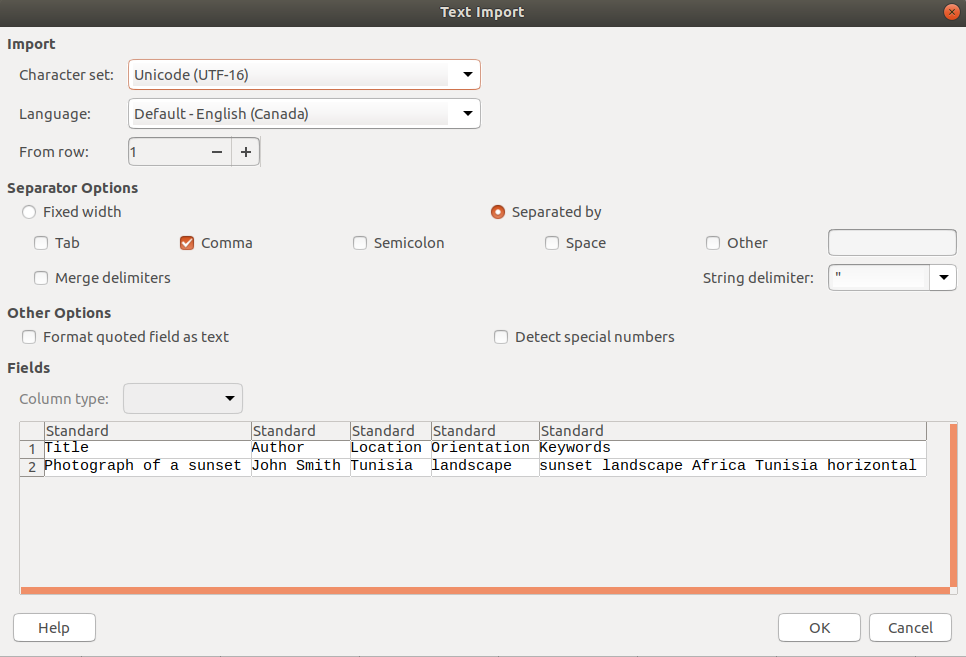
Importing the text into a spreadsheet application.

Ready to Import into MySQL (or another database)
The plain text has now been properly cleaned and structured. It is ready to be imported directly into the MySQL database either using the Terminal or by using the graphical user interface of the PHPMyAdmin web application that is usually installed on a web server that runs MySQL and PHP.